今天zouyee先带各位盘点CNCF上周的一些有趣的事情:
Kubernetes社区GB代表选举结束 Paris Pittman当选
CNCF孵化项目OPA进入毕业流程
上周
helm项目发布v3.5.0功能性版本CoreDNS项目通过Docker镜像仓库放开拉取限制的申请
书接上文《Kubernetes调度系统由浅入深系列:初探》,今天zouyee为大家带来《kuberneter调度由浅入深:框架》,该系列对应版本为1.20.+.
一、前文回顾
在《Kubernetes调度系统由浅入深系列:初探》中,给出整体的交互图,来构建Pod调度的直观感受,我们拓展了一下交互图,如下所示。
注:该交互图非专业UML,还请谅解。
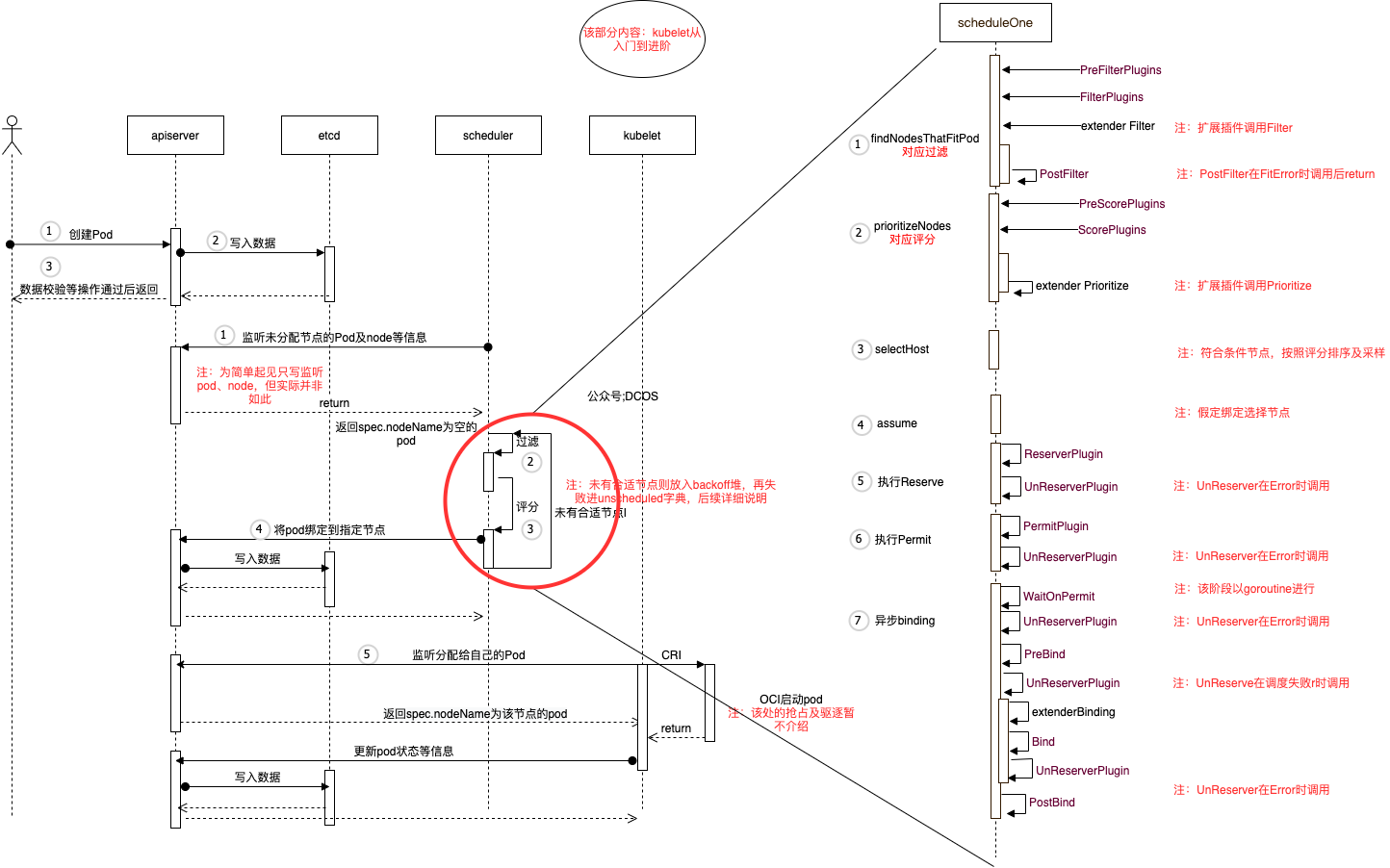
上述以创建一个Pod为例,简要介绍调度流程:
用户通过命令行创建Pod(选择直接创建Pod而不是其他workload,是为了省略kube-controller-manager)
kube-apiserver经过对象校验、admission、quota等准入操作,写入etcd
kube-apiserver将结果返回给用户
同时kube-scheduler一直监听节点、Pod事件等(流程1)
kube-scheduler将spec.nodeName的pod加入到调度队列中,调度系统选择pod,进入调度周期(本文介绍内容)(流程2-3)
kube-scheduler将pod与得分最高的节点进行binding操作(流程4)
kube-apiserver将binding信息写入etcd
kubelet监听分配给自己的Pod,调用CRI接口进行Pod创建(该部分内容后续出系列,进行介绍)
kubelet创建Pod后,更新Pod状态等信息,并向kube-apiserver上报
kube-apiserver写入数据
二、框架背景
Kubernetes 随着功能的增多,代码与逻辑也日益复杂。代码体量及复杂度的提升必然带来维护成本的增加,隐形的增加错误定位和修复的难度。旧版本的Kubernetes调度程序(1.16前)提供了webhooks进行扩展。但有以下缺陷:
用户可以扩展的点比较有限,位置比较固定,无法支持灵活的扩展与调配,例如只能在执行完默认的 Filter 策略后才能调用。
调用扩展接口使用 HTTP 请求,其受到网络影响,性能远低于本地的函数调用。同时每次调用都需要将 Pod 和 Node 的信息进行 序列化与反序列化 操作,会进一步降低性能。
Pod当前的相关信息,无法及时传递(利用调度Cache)。
为了解决上述问题,使调度系统代码精简、扩展性更好,社区从 Kubernetes 1.16 版本开始, 引入了一种新的调度框架- Scheduling Framework 。
Scheduling Framework 在原有调度流程的基础之上, 定义了丰富的扩展点接口,开发者可以通过实现扩展点所定义的接口来实现插件,将插件注册到扩展点。Scheduling Framework 在执行调度流程时,运行到相应的扩展点时,执行用户注册的插件,生成当前阶段的结果。通过这种方式来将用户的调度逻辑集成到 Scheduling Framework 中。Scheduling Framework明确了以下目标:
- 扩展性:调度更具扩展性
- 维护性:将调度器的一些特性移到插件中
- 功能性
- 框架提供扩展
- 提供一种机制来接收插件结果并根据接收到的结果继续或终止
- 提供一种机制处理错误与插件通信
三、框架原理
Framework 的调度流程是分为两个阶段:
- 调度阶段是同步执行的,同一个周期内只有一个 scheduling cycle,线程安全
- 绑定阶段(gouroutine)是异步执行的,同一个周期内可能会有多个 binding cycle在运行,线程不安全
在介绍Framework 的调度流程之前,先介绍上图的调度流程,即schedulerOne的处理逻辑:
a. 调度阶段
1. **过滤**操作即findNodesThatFitPod函数
- 执行PreFilterPlugins
- 执行FilterPlugins
- 执行扩展 Filter
- 若出现FitError,执行PostFilter
2. **评分**操作即prioritizeNodes函数
- 执行PreScorePlugins
- 执行ScorePlugins
- 执行扩展Prioritize
3. 挑选节点即select函数(符合条件节点,按照评分排序及采样选择)
4. 节点预分配即assume(只是预先分配,可收回)
5. 相关调度数据缓存即RunReservePlugins,从该节点开始,后续阶段发生错误,需要调用UnReserve,进行回滚(类似事务)
6. 执行准入操作即RunPermitPlugins
b. 绑定阶段
1. 执行WaitOnPermit,失败时调用RunReservePluginsUnreserve
2. 执行预绑定即RunPreBindPlugins,失败时调用RunReservePluginsUnreserve
3. 执行扩展bingding即extendersBinding,失败时调用RunReservePluginsUnreserve
4. 执行绑定收尾工作即RunPostBindPlugins
扩展点介绍
上述涉及到的各类Plugins(图中紫色部分),针对下图,各位应该看了很多篇了,需要注意的是Unreserve的时机,各插件功能说明如下:
pkg/scheduler/framework/interface.go
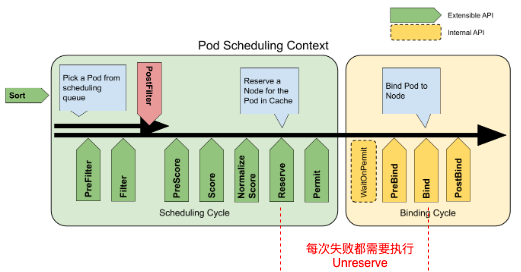
| 扩展点 | 用途说明 |
|---|---|
| QueueSort | 用来支持自定义 Pod 的排序。如果指定 QueueSort 的排序算法,在调度队列里面就会按照指定的排序算法来进行排序,只能enable一个 |
| Prefilter | 对 Pod 信息的预处理,比如 Pod 的缓存等 |
| Filter | 对应旧式的Predicate ,过滤不满足要求的节点 |
| PostFilter | 用于处理当 Pod 在 Filter 阶段失败后的操作,例如抢占等行为 |
| PreScore | 用于在 Score 之前进行一些信息生成,也可以在此处生成一些日志或者监控信息 |
| Score | 对应旧式的Priority,根据 扩展点定义的评分策略挑选出最优的节点(打分与归一化处理) |
| Reserver | 调度阶段的最后一个插件, 防止调度成功后资源的竞争, 确保集群的资源信息的准确性 |
| Permit | 主要提供了Pod绑定的拦截功能,根据条件对pod进行allow、reject或者wait。 |
| PreBind | 在真正 bind node 之前,执行一些操作 |
| Bind | 一个 Pod 只会被一个 BindPlugin 处理,创建Bind对象 |
| PostBind | bind 成功之后执行的逻辑 |
| Unreserve | 在 Permit 到 Bind 这几个阶段只要报错就回滚数据至初始状态,类似事务。 |
四、使用场景
下述为一些关于如何使用调度框架来解决常见调度场景的示例。
联合调度
类似
kube-batch,允许调度以一定数量的Pod为整体的任务。其能够将一个训练任务的多个worker当做一个整体进行调度,只有当任务所有worker的资源都满足,才会将容器在节点上启动。集群资源的动态绑定
Volume topology-aware调度可以通过filter和prebind方式实现。
调度拓展
该框架允许自定义插件,以main函数封装scheduler方式运行。
关于框架部分,该文就介绍到此处,接下里将进入源码阶段,后续内容为调度配置及第三方调度集成的相关内容,敬请关注。
五、参考资料
1. https://kubernetes.io/docs/concepts/scheduling-eviction/kube-scheduler/
2. https://kubernetes.io/docs/concepts/scheduling-eviction/scheduling-framework/
3. https://github.com/kubernetes/enhancements/blob/master/keps/sig-scheduling/624-scheduling-framework/README.md