摘要
- Databricks Serverless计算每天启动数百万台虚拟机,其中绝大部分是数据和 AI 产品,针对如此规模的场景,如何高效地运行基础设施将是一个巨大的挑战。
- 本文介绍了系统性层面的一系列优化,旨在将虚拟机启动耗时减少7倍,最终每天能够节省数千万分钟的计算时间
- 这些优化使 Databricks 能够以最低的成本为Serverless用户提供更低的延迟和高性能的产品体验。
Databricks Serverless计算基础设施横跨三大云服务商以管理数百万台虚拟机,针对如此规模的场景,如何高效地运营基础设施是一项巨大的挑战。通过该文,我们分享最近所做的一些工作,让用户体验到真正的Serverless产品:不单单是提供计算资源,同时包括底层系统(例如完整的 Apache Spark 集群或大型语言模型服务等)均能够在几秒钟内为大规模的数据和 AI 工作负载做好准备。
在我们之前,没有任一Serverless平台能够在几秒钟内运行如此多样化的数据和 AI 工作负载,其耗时关键在于设置 VM 环境。关于如何实现最佳性能,这不仅涉及各种软件包安装,还需要彻底预热运行时环境。我们以 Databricks Runtime(DBR)为例,它需要预热 JVM 的 JIT 编译器,以便从一开始就为客户提供最佳性能。
在这篇博客中,我们介绍了当前开发的一系列系统级相关优化,其旨在将预加载了 Databricks 软件的虚拟机(简称 Databricks VM)的启动时间从分钟缩短到秒级——自我们Serverless平台推出以来,启动效率提高了 7 倍,当前几乎支持所有 Databricks 产品。这些优化涵盖了整个软件栈,从操作系统和容器运行时到托管应用程序,帮助我们每天节省数千万分钟的计算时间,并为 Databricks Serverless客户提供最优性价比的服务。
Databricks虚机启动流程简介

上图描述了虚拟机启动的三个重要阶段:
操作系统启动
Databricks 虚拟机的启动从通用操作系统启动开始:启动内核,启动系统服务,启动容器运行时,最后连接到集群管理器,注:该管理器负责管理所有虚拟机
拉取容器镜像
为了简化运行时资源管理与部署,Databricks将应用程序打包为容器镜像。虚拟机连接到集群管理器后,它将拉取容器基础组件列表(有点类似Kubelet进程),开始从容器镜像仓库下载镜像。这些镜像不仅包括最新的 Databricks Runtime,还包括用于日志处理、虚拟机健康监控、指标上报等平台管理类的基础工具。容器内设置
最后,虚拟机启动工作负载容器,初始化环境并启动服务。以 Databricks Runtime 为例——其初始化过程涉及加载数千个 Java 库,并通过执行一系列精心选择的查询来预热 JVM。我们运行预热查询,强制 JVM 将字节码即时编译(JIT)为常见代码路径的本地机器指令,这确保用户从第一次查询开始就能享受最佳的运行时性能。运行大量的预热查询可以确保系统为所有类型的查询和数据处理需求提供低延迟体验。但是这种查询可能导致初始化过程需要额外消耗几分钟。
针对上述每个阶段的耗时点,我们通过以下方案来降低延迟:
专用Serverless操作系统
对于 Databricks Serverless计算,我们负责管理整个软件栈,因此可以通过构建一个专门的Serverless操作系统,以满足运行短暂虚拟机的需求。具体来说,我们只需包含运行容器所需的基本软件,并调整其启动顺序,使其比通用操作系统更早启动关键服务。我们调整操作系统配置,以优先考虑缓冲 I/O 写入需求,减少启动过程中的磁盘瓶颈。
通过去除不必要的操作系统组件(例如,禁用 USB 子系统)来加速虚拟机启动效率,同时使启动过程更适合云环境。在虚拟机中,操作系统从远程磁盘启动,磁盘内容在启动过程中被拉取到物理主机,云提供商通过预测哪些块扇区更可能被访问以优化该过程。云供应商针对较小的操作系统镜像能够更有效地缓存磁盘内容。
此外,我们定制了Serverless操作系统,以减少启动过程中的 I/O 竞争,因为启动期间通常涉及大量的文件写入。例如,调整系统设置,在内核将文件写入磁盘之前,将更多文件写入缓冲区。同时我们还修改了容器运行时,以减少镜像拉取和创建容器时的阻塞性同步写入问题。我们主要针对短暂、无状态的虚拟机设计了上述优化,在这些虚拟机中,电源中断和系统崩溃导致的数据丢失问题无影响。
延迟容器文件系统
在 Databricks 虚拟机连接到集群管理器后,需要先下载几个GB的容器镜像,然后才能初始化 Databricks Runtime 和其他应用,例如日志处理、指标上报等工具。即使将全部网络带宽和/或磁盘吞吐量用满,下载过程仍可能需要几分钟。另一方面,根据前期的分析,下载容器镜像占据了 76% 的容器启动时间,但启动容器时,只需要 6.4% 的数据即可开始正常工作。
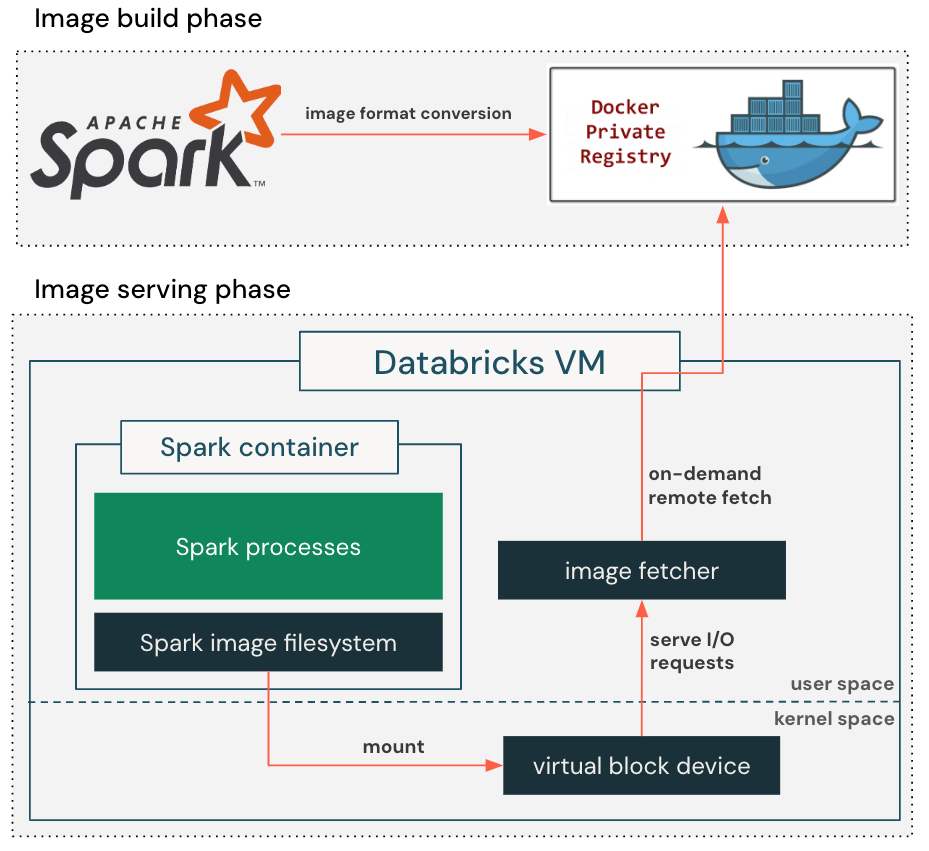
如上图所示,我们使用了懒加载容器文件系统。在构建容器镜像时,我们增加了一个额外的步骤,将基于 gzip 的镜像格式转换为适合懒加载的基于块设备的格式。这使得容器镜像在生产环境中可以表示为一个具有 4MB 扇区的可寻址块设备。
在拉取容器镜像时,我们定制的容器运行时仅需检索设置容器根目录所需的元数据,包括目录结构、文件名和权限,并相应地创建一个虚拟块设备,然后将虚拟块设备挂载到容器中,使应用程序可以立即运行。当应用程序第一次读取文件时,针对虚拟块设备的 I/O 请求将触发镜像获取进程,该进程从远程容器镜像仓库中检索实际的块内容。检索到的块内容会被本地缓存,以防止重复的网络往返请求到容器注册表,减少变动网络延迟对未来读取的影响。
懒加载容器文件系统消除了在启动应用程序之前下载整个容器镜像的需求,将镜像拉取延迟从几分钟减少到仅几秒钟。通过将镜像下载过程分布在更长的时间内,来缓解带宽的压力,避免了限速。
检查点/恢复预初始化容器
最后,我们通过执行一个长时间的容器内设置序列来初始化容器,然后再将虚拟机标记为ready以提供服务。对于 Databricks Runtime,我们预加载所有必要的 Java 类,并预热 Spark JVM 进程。虽然这种方法为用户的初始查询提供了最佳性能,但它显著增加了启动时间。此外,同样的设置过程会在每个 Databricks 启动的虚拟机上重复执行。
我们通过缓存完全预热的状态的容器镜像来解决耗时过多的启动过程。具体来说,我们对预初始化容器进行进程树检查点,并将其作为模板来启动未来相同工作负载类型的实例。在这种设置中,容器被直接“恢复”到一致的初始化状态,完全跳过了重复且昂贵的设置过程。
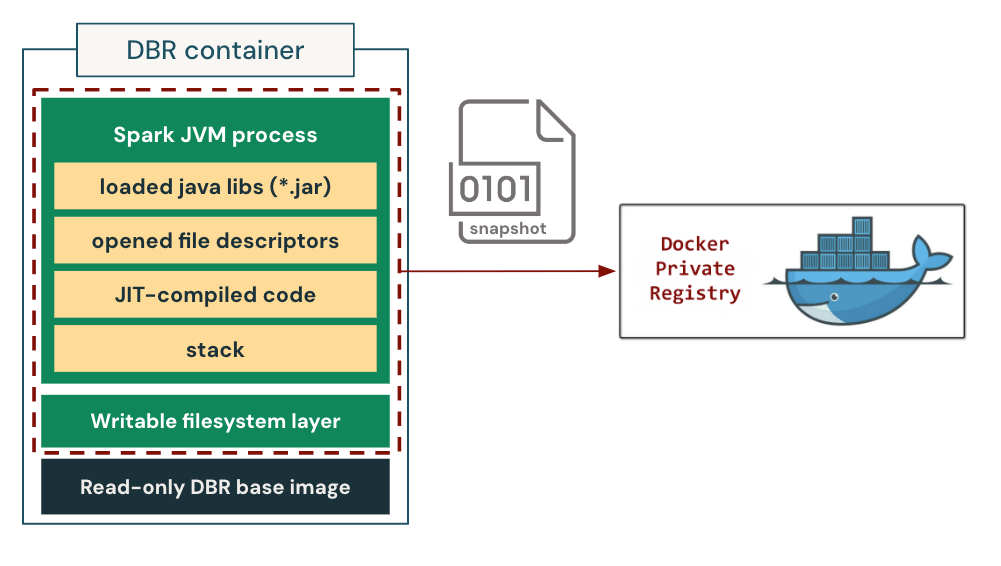
我们在定制的容器运行时中实现并集成了检查点/恢复功能。上图展示了其工作原理。在chekpoint过程中,容器运行时首先冻结容器的整个进程树,以确保状态一致性。然后,它将进程状态转储到磁盘,包括加载的库、打开的文件描述符、整个堆状态(包括 JIT 编译的本地代码)以及堆栈内存。此外,它还保存容器文件系统的可写层,以保留在容器初始化过程中创建/修改的文件。这使得我们可以在以后恢复内存中的进程状态和磁盘上的文件系统状态。我们将检查点打包成一个 OCI/Docker 兼容的镜像,然后像标准容器镜像一样使用容器镜像仓库存储与分发。
虽然从概念上来看较为简单,但它也面临着一些挑战:
Databricks Runtime 必须兼容检查点/恢复
最初Databricks Runtime 并不兼容检查点/恢复,因为(1)Databricks Runtime 可能会访问非通用信息(如主机名、IP 地址、甚至是pod 名称)以支持各种场景,而我们可能会在许多不同的虚拟机上恢复相同的检查点(2)Databricks Runtime 无法处理时间变化场景,因为恢复可能发生在检查点创建后的几天或几周。为了解决这个问题,我们在 Databricks Runtime 中引入了一个检查点/恢复兼容模式。该模式延迟绑定主机特定信息,直到恢复后才执行。它还添加了恢复前和恢复后的钩子,以在检查点/恢复过程中启用自定义逻辑。例如,Databricks Runtime 可以利用这些钩子通过暂停和恢复心跳来管理时间变化,重新建立外部网络连接等。Databricks Runtime 兼容检查点/恢复
检查点捕获的是容器的最终进程状态,因此它由许多因素决定,例如 Databricks Runtime 版本、应用配置、堆大小、CPU 的指令集架构(ISA)等。比如将一个在 64GB 虚拟机上创建的检查点恢复到 32GB 虚拟机上可能会导致内存溢出(OOM)问题,而将一个在英特尔 CPU 上创建的检查点恢复到 AMD CPU 上可能会由于 JVM 的 JIT 编译器是基于 ISA 生成的本地代码,这可能导致非法指令。这对于设计能够跟上 Databricks Runtime 开发和计算基础设施快速发展的检查点提出了巨大的挑战。我们按需创建检查点,创建的检查点随后会通过容器镜像仓库上传并分发,以便具有匹配签名的工作负载可以直接从这些检查点恢复。这种方法不仅简化了检查点生成pipeline的设计,还确保了所有创建的检查点在生产环境中真实可用。恢复的唯一性
从相同的检查点启动多个容器可能会破坏唯一性原则。例如,随机数生成器(RNG)将共享相同的种子,恢复后开始输出相同的随机数序列。我们跟踪初始化过程中创建的 RNG 对象,并利用恢复后钩子重新为 RNG 对象设定种子,以保障它们的唯一性。
通过生产评估,我们发现这一系列优化将 Databricks Runtime 的初始化和预热时间从几分钟缩减到10 秒钟左右。该功能还允许进行更深层次的 JVM 预热,而无需担心时间问题。
结论
Databricks致力于通过持续创新为客户实现最大化价值,同时为客户提供最佳的性价比。这篇博客描述了一系列深层次的系统优化,成功将 Databricks 虚拟机的启动时间缩短了 7 倍。这不仅为Serverless客户提供了更好的性能体验,还使我们能够以最低的价格为客户提供这种级别的用户体验。同时,我们在计算暖池的规模时,将考虑到虚拟机启动时间的缩短,以进一步降低Serverless成本。最后,我们要感谢开源社区,正是从中受益,我们才能将这些优化付诸实践。