从CNCF基金会的成立,到Kubernetes社区蓬勃发展,历经6载,17年异军突起,在mesos、swarm等项目角逐中,拔得头筹,继而一统容器编排,其成功的关键原因可概括为以下几点:
- 项目领导者们的坚守与远见
- 社区的良好的运作与社区文化
- 社区与企业落地的正反馈
虽然针对kubernetes的介绍已经比较多了,但是云原生还是Kubernetes项目的发展都已经迈入深水区,因而今天zouyee为大家带来《kuberneter调度由浅入深》,希望通过接下来的五篇文章,让各位能够系统深入的了解kubernetes调度系统,该系列对应版本为1.20.+,今天带来《Kubernetes调度系统由浅入深系列:初探》
一、调度简介
在开始前,先来看看Kubernetes的架构示意图,其中控制平面包含以下三大组件:kube-scheduler、kube-apiserver、kube-controller-manager。kubelet及kube-proxy组件的分析我们后续单独成章进行讲解,现在我们可以简单给理解上述组件的难易程度排个序,kube-apiserver、kubelet、kube-scheduler、kube-controller-manager、kube-proxy。

如上所述,kube-scheduler是K8S系统的核心组件之一,其主要负责Pod的调度,其监听kube-apiserver,查询未分配 Node的Pod(未分配、分配失败及尝试多次无法分配),根据配置的调度策略,将Pod调度到最优的工作节点上,从而高效、合理的利用集群的资源,该特性是用户选择K8S系统的关键因素之一,帮助用户提升效率、降低能耗。
kube-scheduler 负责将Pod 调度到集群内的最佳节点(基于相应策略计算出的最佳值)上,它监听 kube-apiserver,查询还未分配节点 的 Pod,然后根据调度策略为这些 Pod 分配节点,执行绑定节点的操作(更新Pod的nodeName字段)。
在上述过程中,需要考虑以下问题:
- 如何确保节点分配的公平性
- 如何确保节点资源分配的高效性
- 如何确保Pod调度的公平性
- 如何确保Pod调度的高效性
- 如何扩展Pod调度策略
为解决上述的问题,kube-scheduler通过汇集节点资源、节点地域、节点镜像、Pod调度等信息综合决策,确保Pod分配到最佳节点,以下为kube-scheduler的主要目标:
- 公平性:在调度Pod时需要公平的决策,每个节点都有被分配的机会,调度器需要针对不同节点作出平衡决策。
- 资源高效:最大化提升所有可调度资源的利用率,使有限的CPU、内存等资源服务尽可能更多的Pod。
- 性能:能快速的完成对大规模Pod的调度工作,在集群规模扩增的情况下,依然能确保调度的性能。
- 灵活性:在实际生产中,用户希望Pod的调度策略是可扩展的,从而可以定制化调度算法以处理复杂的实际问题。因此平台要允许多种调度器并行工作,并支持自定义调度器。
二、调度流程
首先我们通过下面的整体的交互图,来构建Pod调度的直观感受。
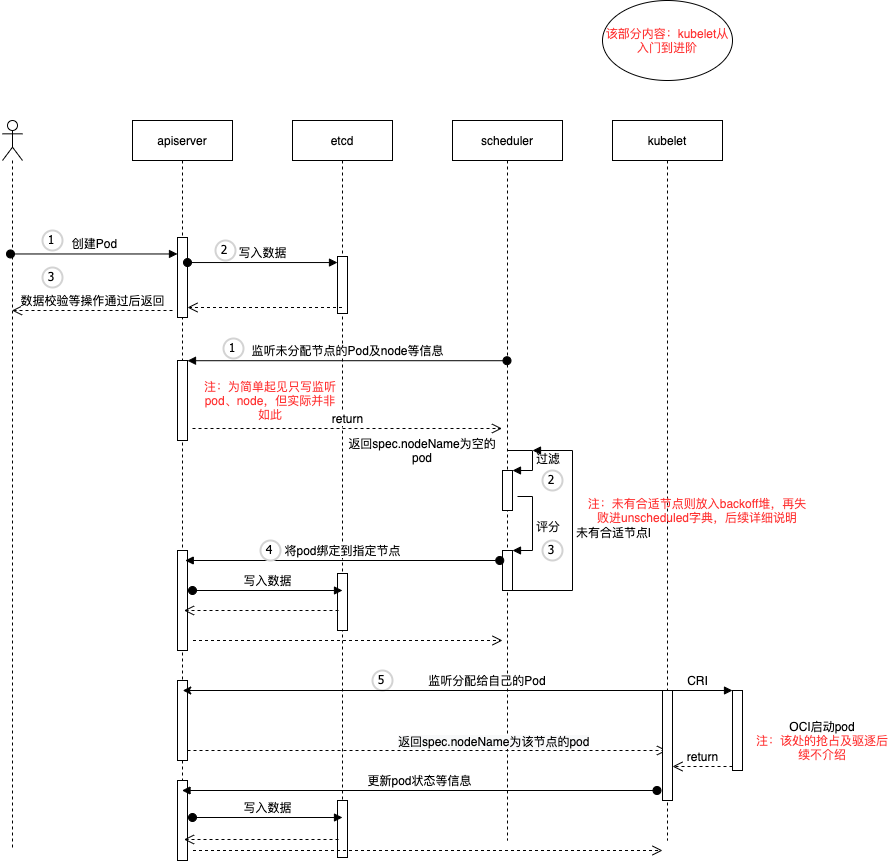
上述以创建一个Pod为例,简要介绍调度流程:
用户通过命令行创建Pod(选择直接创建Pod而不是其他workload,是为了省略kube-controller-manager)
kube-apiserver经过对象校验、admission、quota等准入操作,写入etcd
kube-apiserver将结果返回给用户
同时kube-scheduler一直监听节点、Pod事件等(流程1)
kube-scheduler将spec.nodeName的pod加入到调度队列中,进行调度周期(该周期即位后续介绍内容)(流程2-3)
kube-scheduler将pod与得分最高的节点进行binding操作(流程4)
kube-apiserver将binding信息写入etcd
kubelet监听分配给自己的Pod,调用CRI接口进行Pod创建(该部分内容后续出系列,进行介绍)
kubelet创建Pod后,更新Pod状态等信息,并向kube-apiserver上报
kube-apiserver写入数据
调度周期
kube-scheduler的工作任务是根据各种调度算法将Pod绑定(bind)到最合适的工作节点,整个调度流程分为两个阶段:过滤和评分。流程示意图如下所示。
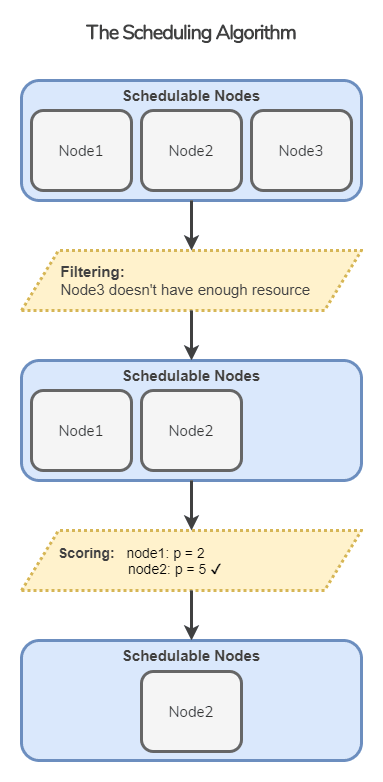
注:以前称之为predicate与priorities,当前统称为过滤与评分,实际效果一致
过滤:输入是所有节点,输出是满足预选条件的节点。
kube-scheduler根据过滤策略过滤掉不满足的节点。例如,如果某节点的资源不足或者不满足预选策略的条件如“节点的标签必须与Pod的Selector一致”时则无法通过过滤。评分:输入是通过过滤阶段的节点,评分时会根据评分算法为通过过滤的节点进行打分,选择得分最高的节点。例如,资源越充足、负载越小的节点可能具有越高的排名。
通俗点说,调度的过程就是在回答两个问题:1. 候选节点有哪些?2. 其中最适合的是哪一个?
如果在过滤阶段没有节点满足条件,Pod会一直处在Pending状态直到出现满足的节点,在此期间调度器会不断的进行重试。如果有多个节点评分一致,那么kube-scheduler任意选择其一。
注:Pod首先进入调度队列,失败后进入backoff,多次失败后进入unschedule,该部分内容后续介绍。
调度算法
当前支持两种方式配置过滤、评分算法:
1. Scheduling Policies:通过文件或者configmap配置Predicate算法(过滤)和 Priorities算法(评分)的算法
2. Scheduling Profiles:当前调度系统为插拔架构,其将调度周期分为 `QueueSort`、`PreFilter`、`Filter`、`PreScore`、`Score`、`Reserve`、`Permit`、`PreBind`、`Bind`、`PostBind`等阶段,通过定制调度周期中不同阶段的插件行为来实现自定义。
下面简单介绍一下通过Scheduling Policies方式配置
pkg/scheduler/framework/plugins/legacy_registry.go
预选(Precates)
| 算法名称 | 算法含义 |
|---|---|
| MatchInterPodAffinity | 检查pod资源对象与其他pod资源对象是否符合亲和性规则 |
| CheckVolumeBinding | 检查节点是否满足pod资源对象的pvc挂载需求 |
| GeneralPredicates | 检查节点上pod资源对象数量的上线,以及CPU 内存 GPU等资源是否符合要求 |
| HostName | 检查Pod指定的NodeName是否匹配当前节点 |
| PodFitsHostPorts | 检查Pod容器所需的HostPort是否已被节点上其它容器或服务占用。如果已被占用,则禁止Pod调度到该节点 |
| MatchNodeSelector | 检查Pod的节点选择器是否与节点的标签匹配 |
| PodFitsResources | 检查节点是否有足够空闲资源(例如CPU和内存)来满足Pod的要求 |
| NoDiskConflict | 检查当前pod资源对象使用的卷是否与节点上其他的pod资源对象使用的卷冲突 |
| PodToleratesNodeTaints | 如果当前节点被标记为taints,检查pod资源对象是否能容忍node taints |
| CheckNodeUnschedulable | 检查节点是否可调度 |
| CheckNodeLabelPresence | 检查节点标签是否存在 |
| CheckServiceAffinity | 检查服务亲和性 |
| MaxCSIVolumeCountPred | 如果设置了featuregate (attachvolumelimit)功能,检查pod资源对象挂载的csi卷是否超出了节点上卷的最大挂载数量 |
| NoVolumeZoneConflict | 检查pod资源对象挂载pvc是否属于跨区域挂载,因为gce的pd存储或aws的ebs卷都不支持跨区域挂载 |
| EvenPodsSpreadPred | 一组 Pod 在某个 TopologyKey 上的均衡打散需求 |
注:其中 MaxEBSVolumeCountPred、 MaxGCEPDVolumeCountPred MaxAzureDiskVolumeCountPred、MaxCinderVolumeCountPred 等云厂商相关预选算法已经废弃
优选(Priorities)
| 算法名称 | 算法含义 |
|---|---|
| EqualPriority | 节点权重相等 |
| MostRequestedPriority | 偏向具有最多请求资源的节点。这个策略将把计划的Pods放到整个工作负载集所需的最小节点上运行。 |
| RequestedToCapacityRatioPriority | 使用默认的资源评分函数模型创建基于ResourceAllocationPriority的requestedToCapacity。 |
| SelectorSpreadPriority | 将属于相同service rcs rss sts 的pod尽量调度在不同的节点上 |
| ServiceSpreadingPriority | 对于给定的服务,此策略旨在确保Service的Pods运行在不同的节点上。总的结果是,Service对单个节点故障变得更有弹性。 |
| InterPodAffinityPriority | 基于亲和性(affinity)和反亲和性(anti-affinity)计算分数 |
| LeastRequestdPriority | 偏向使用较少请求资源的节点。换句话说,放置在节点上的Pod越多,这些Pod使用的资源越多,此策略给出的排名就越低。 |
| BalancedRequestdPriority | 计算节点上cpu和内存的使用率,使用率最均衡的节点最优 |
| NodePreferAvoidPodsPriority | 基于节点上定义的注释(annotaion)记分,注释中如果定义了alpha.kubernetes.io/preferAvoidPods则会禁用ReplicationController或者将ReplicaSet的pod资源对象调度在该节点上 |
| NodeAffinityPriority | 基于节点亲和性计算分数 |
| TaintTolerationPriority | 基于污点(taint)和容忍度(toleration)是否匹配计算分数 |
| ImageLocalityPriority | 基于节点上是否已经下拉了运行pod资源对象的镜像计算分数 |
| EvenPodsSpreadPriority | 用来指定一组符合条件的 Pod 在某个拓扑结构上的打散需求 |